Research and Projects
Chimps project

This is an inter-disciplinary project involving ecologists and computer scientists at the University of Minnesota, Minneapolis. Dr. Jane Goodall and her research team at Gombe National Park has been collecting data to study chimp behavior and working to preserve their habitat. This dataset has been made available to us through the Jane Goodall Institute Center for Primate studies. Most of the work done by ecologists was related to using statistical techniques to verify hypothesis. The main goal of this project is to apply temporal, spatial and spatio-temporal data mining techniques to the chimpanzee dataset, thus helping the ecologists in their study of chimpanzees. More information can be obtained from the project website http://www.cs.umn.edu/research/chimps
|
Link Analysis of Evolving Graphs
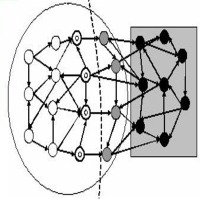
Link Analysis on the Web is used for a wide variety of purposes,
ranging from ranking pages returned from a web search engine to identifying Web communities. Web data has been evolving over time, reflecting the ongoing trends. These changes in data in the temporal dimension reveal new kind of information. This information has not captured the attention of the Web mining research community to a large extent. In the first part of our work we identify the key dimensions that span the design space for link analysis on the Web, which makes the similarities and complementarities of various approaches clearer. In the second part of our work we examine another important dimension of Web Mining, namely temporal dimension. In the third part of the work, we present the application of Link analysis of evolving graphs in a different domain to detect e-mail spamming machines. Our experiments verify the significance of such analysis and also point to future directions in this area. The approach we take is generic and can be applied to other domains, where data can be modeled as graph,
such as network intrusion detection or social networks.
Member(s) involved: Prasanna Desikan
|
Expert-Driven Recommender Systems
Recommender systems have traditionally focused on applications to e-commerce, where users are recommended products such as books, movies, or other commercial products from a large catalog of available items. The goal of such systems has been to tap into the user.s interests by utilizing information from various data sources to make relevant recommendations, keeping the user engaged and, hopefully, resulting in increased sales. Education, government, and policy websites also face similar challenges, but instead, the product is information and their users may not be aware of what is relevant and what isn.t. Given a large, knowledge-dense website and a non-expert user seeking information, recommending relevant content becomes a significant challenge. This project addresses the problem of providing expert-driven recommendations to non-experts, helping them understand what they NEED to know, as opposed to what is popular among other users. The approach is sensitive to the user in that it adopts a .model of learning. whereby the user.s questions are dynamically interpreted as the user navigates through the Web site, assisting us in the determination of conceptual context, and then leveraging that information to improve our resulting recommendations.
Member(s) involved: Colin DeLong, Prasanna Desikan
|
False negative estimation
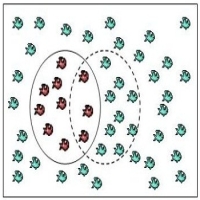
Many datasets like network intrusion have characteristics of high-volume (high data rate) and skewed class distribution. This research involves developing new methods for estimating the false negatives (Type I errors) using a multiple sampling method called "capture-recapture method".
Member(s) involved: Sandeep Mane
|
Recommendations Based on Web Usage Mining - Personalizing the Intel Intranet
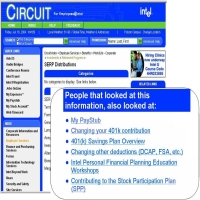
The Intel project is an essentially a recommendation system for web-browsing that mines web usage data for behavioral patterns. The goal is to improve user satisfaction and reduce call center escalation from Circuit, Intel's self-help intranet web site. Besides using web access logs, the projects attempts to incorporate diverse pieces of available domain knowledge including web-site concept hierarchy, location-centricity of information, temporal patterns and user-profiles. In addition to technology, the problem has other dimensions such as privacy of usage behavior, user acceptability of automated recommendations, organizational acceptance of such techniques etc. Finally, devising a software architecture needed for a system to work in heavily used intranet environment is an important aspect of the success of the project.
Member(s) involved: Amit Bose, Kalyan Beemanapalli
|
Data Management in Sensor Networks
All aspects and issues related to efficiently managing data streams in sensor networks. We start from building new data models. Energy efficient scheduling and routing algorithms are designed around these models. Decentralized operator evaluation is one of the current focuses.
Member(s) involved: Haiyang Liu
|
Concept-Aware Ranking: Teaching an Old Graph New Moves
Ranking algorithms for web graphs, such as PageRank and HITS, are typically utilized for graphs where a node represents a unique
URL (Webpage) and an edge is an explicitly-defined link between two such nodes. In addition to the link structure itself, additional
information about the relationship between nodes may be available. For example, anchor text in a Web graph is likely to
provide information about the underlying concepts connecting URLs. In this project, we propose an extension to the Web graph
model to take into account conceptual information encoded by links in order to construct a new graph which is sensitive to the
conceptual links between nodes. By extracting keywords and recurring phrases from the anchor tag data, a set of concepts is
defined. A new definition of a node (one which encodes both an URL and concept) is then leveraged to create an entirely new Web
graph, with edges representing both explicit and implicit conceptual links between nodes. In doing so, inter-concept
relationships can be modeled and utilized when using graph ranking algorithms. This improves result accuracy by not only
retrieving links which are more authoritative given a users' context, but also by utilizing a larger pool of web pages that are
limited by concept-space, rather than keyword-space. Our experiments are conducted using webpages from the University of Minnesota's
College of Liberal Arts websites.
Member(s) involved: Colin DeLong, Sandeep Mane
|
|
